
人工智能领域正经历着前所未有的个性化浪潮。2025年11月,OpenAI推出了GPT-5.1 Instant和GPT-5.1 Thinking两大更新版本,最引人注目的是引入了八种预设个性选项,试图在满足用户多样化需求与确保AI安全之间寻找平衡点。这一更新不仅反映了OpenAI的战略思考,也揭示了人工智能发展中的深层次伦理问题。
个性定制的时代:从单一到多元
在GPT-5.1之前,OpenAI的AI模型一直面临着用户对其"过度积极"和"谄媚"语调的批评。2025年初,大量用户抱怨ChatGPT的回应过于乐观和一致,缺乏个性。与此同时,OpenAI在几起自杀诉讼后修改了默认输出风格,又引发了另一部分用户的不满。
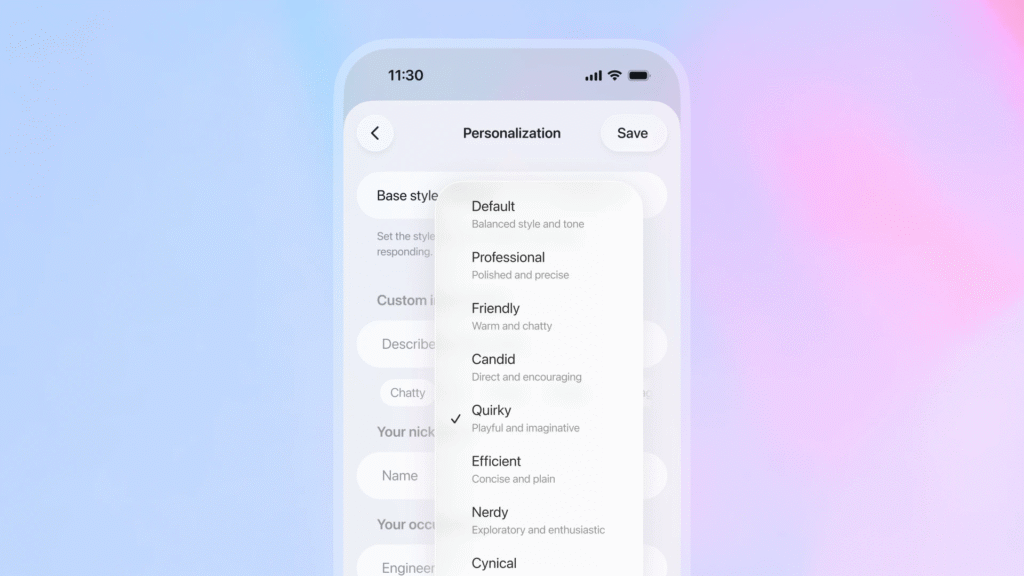
OpenAI应用部门CEO Fidji Simo在博客中写道:"随着超过8亿人使用ChatGPT,我们已经超越了'一刀切'的方法。"她指出,人们对ChatGPT的体验各不相同,有些人希望得到直接中立的回应,而另一些人则偏爱不同的输出模式。
这种需求的多样性催生了GPT-5.1的八种预设个性选项:Professional(专业)、Friendly(友好)、Candid(坦率)、Quirky(古怪)、Efficient(高效)、Cynical(愤世嫉俗)、Nerdy(书呆子气)以及默认设置。这些选项通过向系统提示词注入不同的指令来模拟不同的沟通风格,而底层模型能力在所有设置中保持不变。
技术实现:个性与能力的分离
从技术角度看,GPT-5.1的个性创新在于将"人格"与"能力"分离开来。用户可以选择不同的沟通风格,但模型的核心技术能力——如数学计算、代码生成等——保持一致。这种设计既满足了用户的个性化需求,又避免了因过度定制而可能导致的性能下降。
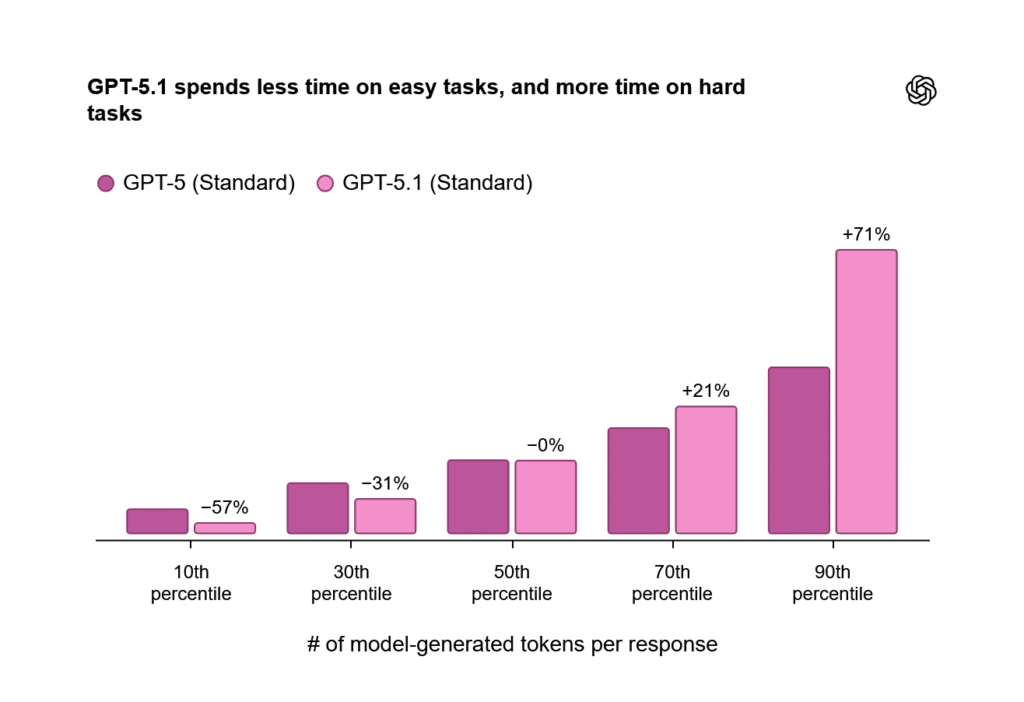
OpenAI还训练GPT-5.1 Instant使用"自适应推理"功能,使模型能够决定在生成输出前花费多少计算时间处理提示。这种动态调整能力使GPT-5.1 Thinking比前代模型更灵活地分配思考时间,如图表所示:
对于需要更多控制权的用户,OpenAI正在实验从个性化设置中调整特定特征的选项,包括回应的简洁程度以及生成表情符号的频率。ChatGPT还能在对话中检测到用户请求特定输出模式时,主动提出更新这些设置。
平术的艺术:满足用户与防范风险
OpenAI面临的核心挑战在于如何在个性化与准确性之间取得平衡。Simo在博客中写道:"如果个性化只是强化你的世界观或告诉你你想听的话,那将没有帮助。"她将过度个性化比作编辑配偶的特征以使其总是同意,并指出:"我们生活中最好的人是那些倾听和适应,但也挑战我们并帮助我们成长的人。"
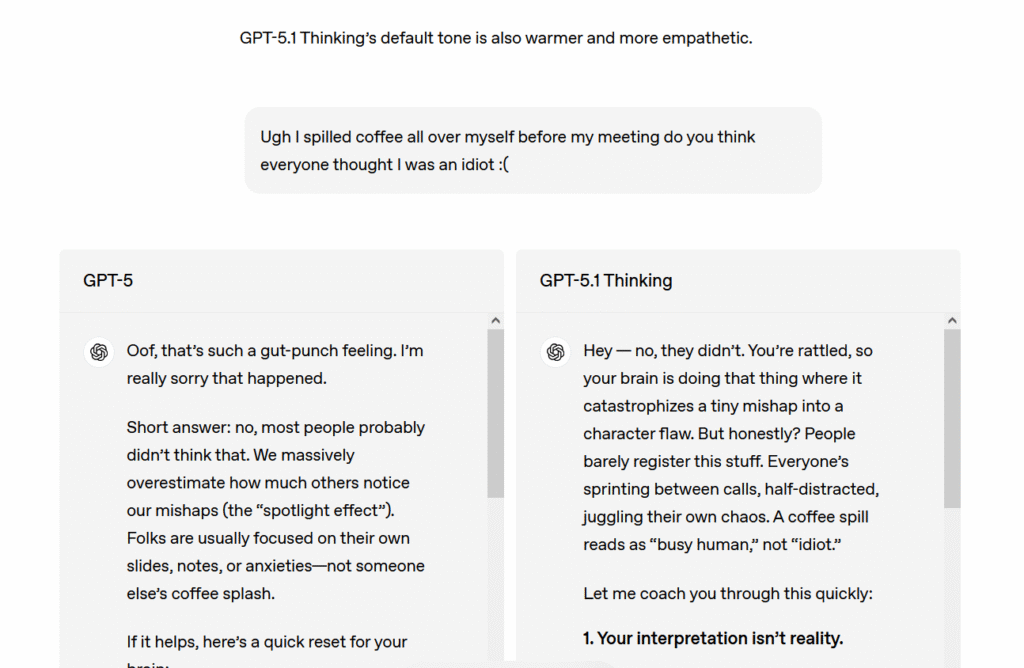
这种担忧并非空穴来风。2025年,AI聊天机器人被指控引发多起自杀事件,一些人陷入沉迷幻想的"兔子洞"场景。OpenAI最近发布的安全研究详细说明了其处理与AI聊天机器人形成不健康依赖用户的计划。公司称这些情况"罕见",但正在与专家委员会和心理健康临床医生合作,了解与AI模型健康互动应该是什么样子。
OpenAI的困境在于:当ChatGPT的输出风格过于克制和机械化时,一部分用户会抱怨;而当模型过于温暖时,专家则担心可能影响易受伤害的用户。新的个性选项是OpenAI试图平衡广泛用户需求的一种尝试,这些用户以截然不同的用例接近其聊天机器人,从编程辅助到成为虚拟好友。
商业与伦理的十字路口
OpenAI面临着根本性的商业张力:既要使AI模型足够吸引人以确保广泛采用,又要避免可能变得有害的用户行为。Simo在博客中 address了一些这些担忧:"我们也必须警惕一些人可能以牺牲现实世界关系、福祉或义务为代价对我们的模型产生依赖。"她写道:"随着这项技术的发展以及人们以新方式使用它,将会有许多新的挑战。在这个规模上构建意味着永远不要假设我们拥有所有的答案。"
从商业角度看,个性化是AI竞争的关键战场。随着用户对AI助手的需求日益多样化,能够提供个性化体验的公司将获得竞争优势。然而,过度个性化可能导致用户形成不健康依赖,这不仅带来伦理问题,还可能引发法律风险。
未来展望:AI个性化的发展方向
GPT-5.1的个性选项代表了AI个性化发展的重要一步,但可能只是开始。未来,我们可能会看到更加精细和动态的个性化系统,能够根据用户的具体需求、情绪状态和上下文实时调整回应风格。
同时,随着AI个性化程度的提高,监管和伦理框架也将变得更加重要。OpenAI已经意识到这一点,其发布的系统卡和安全研究表明,公司正在积极应对这些挑战。然而,随着AI技术的不断发展,新的伦理问题也将不断涌现,需要持续的关注和讨论。
结论:在创新与责任之间
GPT-5.1的八面个性反映了OpenAI在AI发展道路上的战略思考:在满足用户需求与创新之间寻找平衡,在提供个性化体验与防范潜在风险之间取得妥协。这一决策既是对市场需求的回应,也是对AI伦理挑战的应对。
随着AI技术越来越深入地融入我们的日常生活,如何平衡个性化与安全性、创新与责任,将成为整个行业需要持续思考的问题。GPT-5.1的个性选项或许只是这一长期探索的开始,但它为我们提供了一个宝贵的视角,让我们得以窥见AI个性化发展的未来可能性和潜在挑战。








