
人工智能领域在2025年迎来了多项重大技术突破,从多模态模型到语音合成,从大模型到小模型,AI技术正在以前所未有的速度发展和创新。本文将深入剖析近期AI领域的热点技术,分析其核心优势与应用价值,并探讨这些技术突破对行业未来的深远影响。
可灵AI主体库:解决AI变脸问题的新方案
可灵AI近期发布的「主体库」技术为O1多模态视频模型添加了长期记忆能力,这一创新彻底解决了AI视频中角色"变脸"的痛点问题。通过主体库技术,可灵AI实现了角色一致性超过96%的突破性成果,让AI角色在不同场景中保持高度一致的视觉表现。
技术实现与应用场景
主体库技术的实现流程简洁高效,用户只需上传单张角色图片,系统即可自动完成3D视角补全和多光线变体生成,并支持跨场景一键调用。这种三步流程(上传、补全、调用)极大地降低了技术使用门槛,使创作者能够轻松实现高质量的角色一致性效果。
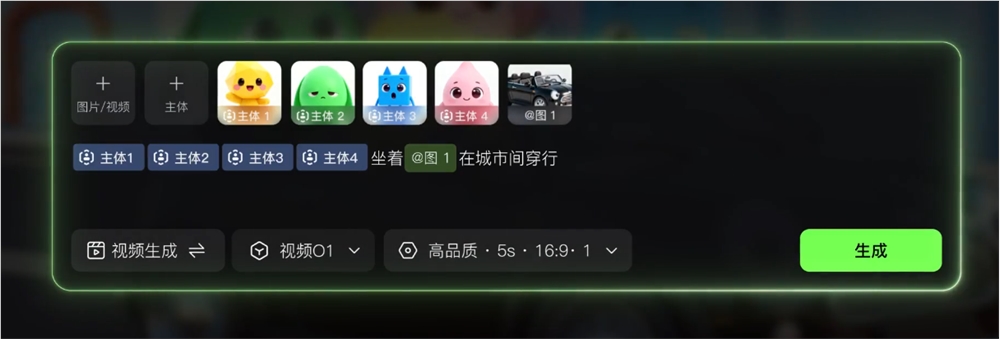
该技术特别适用于影视制作、游戏开发、虚拟主播等需要保持角色一致性的场景。通过AI智能描述功能,系统能自动提取关键词并提升生成成功率,进一步优化了用户体验。
行业意义与未来展望
主体库与O1模型的统一入口实现了文本-图像-视频的无缝衔接,标志着AI多模态技术向实用化迈出了重要一步。这一技术的突破不仅解决了行业痛点,也为AI在创意内容生产领域的应用开辟了新路径。未来,随着技术的不断优化,主体库有望在更多场景中发挥作用,推动AI内容创作进入新阶段。
阿里Qwen3-TTS:多语言语音合成的新标杆
阿里巴巴推出的Qwen3-TTS语音合成模型在2025年引起了行业广泛关注。该模型具备零样本、多角色、跨语言等特性,在字错误率(WER)指标上显著优于主流商用模型,为语音合成领域树立了新的技术标杆。
技术优势与创新点
Qwen3-TTS的最大亮点在于其卓越的多语言支持能力,该模型支持10种语言和9种中国方言,覆盖范围广泛。同时,它提供了49种高品质音色,能够满足不同场景下的个性化需求。这些特性使其在教育、直播、客服等多元应用场景中展现出巨大潜力。
与市场上其他语音合成模型相比,Qwen3-TTS在保持高合成质量的同时,还实现了低延迟和自然流畅的语音输出。这种平衡性能使其成为实时交互应用的理想选择。
应用场景与市场前景
Qwen3-TTS的多语言支持能力使其特别适合全球化应用场景。在教育领域,它可以为不同语言背景的学生提供个性化的语音学习材料;在客服领域,它能够实现多语言客户服务的无缝切换;在内容创作领域,它为创作者提供了多样化的声音选择。
随着语音交互在各类应用中的普及,Qwen3-TTS这类高质量语音合成模型的市场需求将持续增长。阿里巴巴通过开源该模型(https://modelscope.cn/studios/Qwen/Qwen3-TTS-Demo),将进一步推动语音合成技术的发展和应用创新。
腾讯混元2.0:国内大模型新高度
腾讯发布的新一代自研大模型混元2.0代表了国内大模型技术的最新进展。该模型包含Think和Instruct两个版本,在推理能力和指令遵循能力方面表现出色,特别是在数学、科学和代码等复杂任务中展现出优异性能。
技术架构与性能突破
混元2.0采用了MoE(Mixture of Experts)架构,这一设计使其推理速度提升了40%,在保持高性能的同时优化了计算效率。Think版模型在国际数学奥林匹克竞赛(IMO)和哈佛-MIT数学竞赛中分别达到了83.1%和81.7%的准确率,展现了强大的逻辑推理能力。

在商业化方面,腾讯云API的定价仅为GPT-4o的45%,同时支持企业私有化部署,这一策略大大降低了企业使用先进AI模型的门槛,有助于推动AI技术在各行业的广泛应用。
行业影响与战略意义
混元2.0的发布不仅提升了腾讯在AI领域的竞争力,也为国内大模型技术的发展注入了新动力。其优异的性能表现和合理的定价策略,将促使整个行业重新思考大模型的商业化路径和技术发展方向。
特别值得注意的是,混元2.0在保持技术领先的同时,也注重实际应用价值,这种"技术与应用并重"的发展思路,代表了未来大模型技术发展的重要方向。随着更多类似混元2.0的模型出现,AI技术将更深入地融入各行各业,推动产业数字化转型。
美团LongCat-Image:中文图像生成的新突破
美团LongCat团队推出的LongCat-Image图像生成模型以6B参数规模实现了高性能与低门槛的完美结合,尤其在中文文字生成和图像编辑方面表现出色,达到了开源SOTA(State-of-the-Art)水平。
技术特点与创新点
LongCat-Image通过系统性训练策略和数据工程,确保了在多样化指令下仍能保持高效性能和准确性。该模型在图像编辑领域展现了强大的指令遵循和视觉一致性能力,能够精确理解并执行复杂的编辑指令。

在中文文字生成方面,LongCat-Image针对中文文字的特殊性进行了优化,能够支持复杂笔画结构汉字的渲染,解决了现有模型中中文文字生成质量不高的痛点。这一特性使其在广告设计、内容创作等需要高质量中文文字生成的场景中具有重要应用价值。
开源生态与行业贡献
LongCat团队选择开源这一模型,旨在构建一个透明、开放、协作的生态系统,鼓励开发者参与模型的使用与共建。这种开放策略不仅加速了技术的迭代和创新,也为国内AI开源生态的发展做出了积极贡献。
通过开源,LongCat-Image的代码和模型已向公众开放(https://longcat.ai/),开发者可以基于此进行二次开发和应用创新,这将进一步推动AI技术在图像生成领域的应用和发展。
京东云JoyBuilder:推动具身智能规模化
京东云JoyBuilder平台的最新升级成功支持了GR00T N1.5千卡级训练,这一突破标志着具身智能技术向规模化落地迈出了重要一步。通过全栈优化,JoyBuilder将训练效率提升了3.5倍,显著加速了具身智能的发展进程。
技术突破与性能提升
JoyBuilder平台的关键升级使其能够支撑更大规模的模型训练,这为具身智能技术的发展提供了强大算力支持。平台在训练效率上的3.5倍提升,不仅降低了训练成本,也缩短了模型迭代周期,使研发团队能够更快地验证新想法和优化模型性能。
该平台还支持最新的LeRobot训练数据协议,这使其在具身智能领域确立了行业领先地位。通过与GR00T模型的深度集成,JoyBuilder为具身智能的研发和应用提供了全方位支持。
应用前景与行业影响
具身智能作为AI技术的重要分支,专注于让AI系统具备物理交互和环境感知能力。JoyBuilder平台的升级将加速具身智能在机器人、自动驾驶、智能家居等领域的应用落地。
随着训练效率的提升和算力的增强,具身智能系统将能够处理更复杂的任务,在更多实际场景中发挥作用。这不仅将改变人机交互的方式,也将为各行业的数字化转型提供新的技术支撑。
英伟达NVARC:小模型的大能量
英伟达推出的4B小模型NVARC在最新ARC-AGI2评测中以27.64%的优异成绩击败了GPT-5Pro,这一结果震惊了整个AI行业。NVARC展示了小模型在特定任务上的强大性能和成本优势,为AI模型的发展提供了新思路。
技术创新与优势分析
NVARC采用创新的零预训练深度学习方法,避免了传统大规模数据集的领域偏见和数据依赖问题。这一策略使模型能够更好地适应新任务,减少了过拟合的风险。
在数据方面,NVARC利用GPT-OSS-120B生成高质量合成谜题,这种数据生成策略不仅降低了实时计算资源需求,还提高了模型的泛化能力。同时,NVARC的TTFT(Time To First Token)技术使其能够快速适应新任务规则,进一步提升了模型效率。
成本效益与行业启示
NVARC的单任务成本仅为GPT-5 Pro的1/36,这一惊人的成本优势使其在资源受限的场景中具有极高的应用价值。小模型的高效性不仅体现在成本上,还体现在部署和维护的便利性上。
NVARC的成功挑战了"越大越好"的模型发展思路,证明了在特定任务上,精心设计的小模型可以超越通用大模型。这一发现将为AI模型的设计和应用提供新的方向,推动AI技术向更高效、更经济的方向发展。
微博AI手机:人机交互的新边界
微博CEO王高飞关于豆包AI手机能否自主发微博的回应,引发了业界对AI手机操作能力的广泛讨论。尽管AI手机已具备自主发微博的能力,但仍需用户确认,这反映了当前AI技术在自主决策方面的局限性。
技术现状与挑战
豆包AI手机在主流应用中面临登录问题,部分游戏类应用能够检测到AI控制,这限制了AI助手的使用范围。这些挑战暴露了当前AI技术在模拟人类行为和理解复杂应用环境方面的不足。
王高飞的回应揭示了AI操作能力的现状:虽然AI技术已取得长足进步,但在需要精确理解人类意图和应对复杂应用环境的场景中,仍存在明显局限。这表明AI技术的发展还有很长的路要走。
未来发展方向
AI手机的发展方向将是提升对复杂应用环境的理解和适应能力,增强与人类用户的自然交互。未来的AI助手需要更好地理解上下文,预测用户意图,并在不引起应用系统警觉的情况下完成任务。
同时,随着AI技术的进步,应用开发者也需要思考如何更好地支持AI助手,为AI与人类用户提供更平等、更友好的交互环境。这种技术与应用的双向进步,将推动AI手机向更成熟、更实用的方向发展。
微软VibeVoice-Realtime:实时语音合成新突破
微软推出的VibeVoice-Realtime-0.5B模型是一款轻量级的实时文本转语音(TTS)系统,支持流式输入和长篇语音输出。该模型在延迟优化和语音合成质量方面取得了显著进展,为实时交互应用提供了新的技术选择。
技术特点与创新设计
VibeVoice-Realtime的最大亮点在于其极低的响应速度,能够在300毫秒内开始生成语音,这一性能使其非常适合实时交互应用。模型采用交错窗口设计,有效优化了延迟并提升了语音合成质量。
在技术实现上,VibeVoice-Realtime使用低延迟的声学标记器,以7.5赫兹的速度生成声学特征,这大大优化了长篇语音合成的效率。同时,模型在LibriSpeech测试中取得了2.00%的字错误率,表现优于同类产品。
应用场景与市场潜力
VibeVoice-Realtime的实时特性使其在多种场景中具有重要应用价值。在智能客服领域,它可以实现更自然、更流畅的语音交互;在内容创作领域,它可以快速将文本转换为高质量的语音内容;在辅助技术领域,它可以为视障人士提供更及时的语音反馈。
AI技术发展趋势与展望
通过对近期AI领域多项技术突破的分析,我们可以清晰地看到AI技术正在向专业化、高效化、低成本方向发展。这些趋势不仅反映了技术本身的进步,也揭示了AI应用市场的需求变化。
专业化趋势
从可灵AI的主体库到美团的LongCat-Image,AI技术正从通用模型向专业领域深耕。这种专业化趋势使AI系统能够更好地解决特定场景下的复杂问题,提供更精准、更有效的解决方案。
专业化发展的优势在于:一方面,针对特定任务优化的模型能够取得更好的性能表现;另一方面,专业领域的深度理解使AI系统能够更好地满足行业需求,创造更大价值。未来,我们将看到更多针对垂直领域的专业化AI模型出现。
高效化趋势
从腾讯混元2.0的MoE架构到英伟达NVARC的高效设计,AI模型正朝着更高效率的方向发展。这种高效化不仅体现在计算效率上,也体现在能源消耗和资源利用上。
高效化发展的意义在于:降低AI技术的使用门槛,使更多企业和个人能够受益于AI技术;减少资源消耗,降低AI技术的环境影响;加速技术迭代,促进创新更快地转化为实际应用。未来,AI模型的设计将更加注重效率与性能的平衡。
低成本趋势
NVARC的成本效益分析展示了AI技术向低成本方向发展的巨大潜力。随着模型优化和算法创新,高质量AI服务的成本将持续下降,这将进一步扩大AI技术的应用范围。
低成本发展的推动因素包括:模型小型化、训练数据优化、硬件加速等。这些因素共同作用,使AI技术不再是大型企业的专属工具,而是中小企业甚至个人也能负担得起的资源。未来,AI技术的普惠性将显著增强。
结论与展望
2025年的AI技术突破展示了行业的创新活力和发展潜力。从多模态模型到语音合成,从大模型到小模型,AI技术正在不断突破边界,拓展应用场景。这些技术进步不仅解决了行业痛点,也为AI在各领域的应用开辟了新路径。
未来,随着专业化、高效化、低成本趋势的深入发展,AI技术将更加贴近实际需求,创造更大价值。同时,我们也需要关注AI技术带来的伦理、安全等问题,确保技术的发展与人类福祉相协调。
在这个快速发展的AI时代,持续关注技术趋势、把握创新方向,将有助于我们更好地应对未来挑战,抓住发展机遇。AI技术的未来充满无限可能,让我们共同期待更多突破性成果的出现。










