在人工智能领域,多模态大模型正以前所未有的速度演进,而智谱AI最新推出的GLM-4.6V系列模型,无疑是这一领域的重要里程碑。作为一款融合视觉理解与工具调用能力的创新产品,GLM-4.6V不仅突破了传统视觉模型的局限,更实现了从感知到行动的完整闭环,为AI应用开辟了全新可能性。
多模态大模型的新标杆
GLM-4.6V是智谱AI精心打造的多模态大模型系列,包含两个主要版本:面向云端与高性能集群场景的基础版GLM-4.6V(106B-A12B),以及面向本地部署与低延迟应用的轻量版GLM-4.6V-Flash(9B)。这一双版本策略确保了模型在不同应用场景下的灵活性与适用性。

模型最引人注目的特性是其强大的长上下文处理能力,上下文窗口高达128k tokens,理论上可理解长达150页的复杂文档、200页PPT或1小时的视频内容。这一能力使得GLM-4.6V在处理复杂信息时游刃有余,支持跨文档对比分析和长视频关键事件定位等高级应用。
突破性的视觉工具调用能力
GLM-4.6V最大的创新点在于首次将工具调用能力原生融入视觉模型,实现了从视觉感知到可执行行动的完整闭环。这一突破性功能使模型能够直接使用图像、截图等作为工具参数,无需繁琐的文字描述,极大减少了信息损失,同时还能处理工具返回的多模态结果,如统计图表、网页截图等。
这一能力在多个场景中展现出巨大价值:在电商领域,用户可以直接上传商品图片,模型即可识别购物意图,搜索同款商品并生成导购清单;在前端开发中,开发者上传网页截图或设计稿,模型能精准复刻生成代码,并支持多轮交互修改;在内容创作中,模型能处理图像、视频、文本等多种输入形式,生成高质量的图文混排内容。
性能评测与优势分析
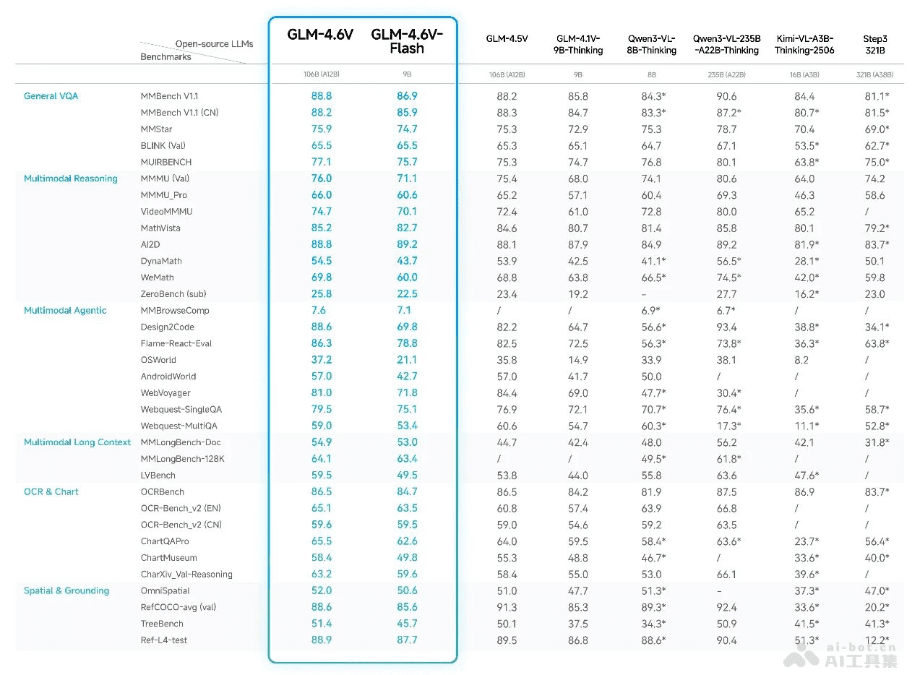
在MMBench、MathVista、OCRBench等30多个多模态评测基准的验证中,GLM-4.6V相比上一代模型有显著提升,尤其在多模态交互、逻辑推理和长上下文处理等关键能力上达到顶尖水平。
令人瞩目的是,9B版本的GLM-4.6V-Flash整体表现已超过Qwen3-VL-8B(8B参数量),在多模态任务中展现出更高的效率和性能。而106B参数、12B激活的GLM-4.6V,其性能比肩2倍参数量的Qwen3-VL-235B,证明其在参数效率上的显著优势,能在更少的计算资源下达到类似甚至更好的性能水平。
核心技术亮点解析
自主工具调用系统
GLM-4.6V的自主工具调用系统是其区别于其他多模态模型的关键。这一系统允许模型基于视觉输入自主决定并调用适当的工具,处理更为复杂的视觉任务。无论是图文混排内容的理解与生成,还是识图购物与导购,甚至是需要多步骤推理的Agent场景,GLM-4.6V都能胜任。
超长上下文处理机制
128k的上下文窗口是GLM-4.6V的另一大亮点。这一能力使模型能够在单次推理中处理多个长文档或长视频,无需分段处理。对于需要综合分析大量信息的应用场景,如学术研究、法律文档分析等,这一功能具有不可替代的价值。
前端开发辅助能力
GLM-4.6V在前端开发方面的表现尤为突出。其代码能力经过专门优化,能够实现像素级的前端复刻,将设计稿快速转化为可运行的网页代码。更重要的是,它支持基于截图的多轮视觉交互修改,大大缩短了"设计稿到可运行页面"的链路,为开发者提供了前所未有的便利。
实际应用场景与案例
智能图文创作
GLM-4.6V在智能图文创作领域展现出强大能力。用户只需输入主题或提供图文混杂的资料,模型就能自动生成结构清晰、图文并茂的内容。这一功能对于社交媒体运营、公众号内容创作等场景尤为有用,能够显著提高内容生产效率。
例如,用户可以仅输入"2025国际乒联混合团体世界杯中国队成绩"这样的简单指令,GLM-4.6V就能自动搜索相关信息,生成一篇图文并茂的新闻报道,包含比赛结果、精彩瞬间和选手采访等内容。
视觉驱动的智能购物
在电商领域,GLM-4.6V的视觉识别与工具调用能力完美结合,创造了全新的购物体验。用户可以直接上传商品图片,模型识别购物意图后,自动搜索同款商品、进行比价,并生成详细的导购清单。
这一功能不仅简化了购物流程,还能帮助用户发现更多相似商品,做出更明智的购买决策。对于电商平台而言,这一功能也能提高转化率,增强用户粘性。
前端开发加速器
GLM-4.6V在前端开发中的应用堪称革命性。开发者上传网页截图或设计稿后,模型能够精准复刻生成代码,包括布局、样式和交互逻辑。更令人印象深刻的是,它支持基于截图的多轮视觉交互修改,开发者可以指出需要调整的部分,模型即时更新代码。
这一功能大大缩短了前端开发周期,特别是对于原型设计和快速迭代阶段,能够显著提高开发效率。对于非专业开发者而言,也降低了前端开发的门槛。
长文档与视频理解
GLM-4.6V的长上下文处理能力使其在处理复杂文档和视频内容时表现出色。研究人员可以上传多篇学术论文,模型能够进行跨文档对比分析,提取关键信息;视频创作者可以上传长视频,模型能够定位关键事件,生成内容摘要。
这一功能在学术研究、内容创作、知识管理等多个领域都有广泛应用价值,能够帮助用户高效处理和理解大量信息。
多模态智能客服
GLM-4.6V的多模态交互能力使其成为智能客服的理想选择。客服系统可以结合用户上传的图片和文本描述,提供更精准的解答和建议。例如,用户可以上传产品故障照片,客服系统能够识别问题并提供解决方案。
这种多模态交互不仅提高了问题解决的准确性,还能增强用户体验,减少沟通成本。对于需要处理复杂视觉信息的客服场景,如产品设计咨询、技术支持等,这一功能尤为有用。
部署与使用方式
GLM-4.6V提供了多种部署和使用方式,满足不同用户的需求:
本地部署:技术爱好者可以从GitHub或其他开源平台下载代码和模型权重,在本地电脑或服务器上运行模型,享受完全的控制权和隐私保护。
云端调用:开发者可以通过访问智谱开放平台,注册账号获取API密钥,通过网络请求调用云端模型,无需关心基础设施维护。
在线体验:普通用户可以直接访问z.ai或智谱清言APP/网页版,选择GLM-4.6V模型,上传图片或输入文字,点击"推理"查看结果,体验模型的强大功能。
应用集成:企业可以将模型通过API或本地部署的方式接入到自己的软件或系统中,实现特定功能,如智能客服、内容创作辅助等。
推理框架支持:GLM-4.6V支持多种推理框架,如SGLang、transformers等,开发者可以根据需求选择合适的框架,结合GPU等硬件高效运行模型。
技术创新与行业影响
GLM-4.6V的推出不仅是智谱AI的技术成果,更是多模态AI领域的重要进展。其创新之处主要体现在三个方面:
首先,GLM-4.6V实现了视觉模型与工具调用能力的深度融合,打破了传统视觉模型仅限于理解的局限,实现了从感知到行动的闭环。这一创新为AI应用开辟了全新可能性,特别是在需要视觉引导行动的场景中。
其次,GLM-4.6V在参数效率上的突破令人瞩目。同等性能下,其计算需求显著低于同类模型,这大大降低了AI应用的成本门槛,使更多企业和个人能够享受到先进AI技术带来的便利。
最后,GLM-4.6V的开源策略促进了技术共享与协作。通过GitHub和HuggingFace等平台,开发者可以获取模型代码和权重,基于此进行二次开发和优化,推动整个多模态AI领域的进步。
未来展望
GLM-4.6V的发布标志着多模态AI技术进入了一个新阶段。展望未来,我们可以期待以下发展方向:
更强的多模态融合能力:未来模型将能更自然地融合视觉、听觉、文本等多种模态信息,实现更接近人类的多模态交互体验。
更高效的推理机制:随着算法优化和硬件进步,模型的推理速度将进一步提升,实现更实时的多模态交互。
更专业的领域适配:针对医疗、法律、教育等专业领域的定制化多模态模型将不断涌现,提供更精准的专业服务。
更广泛的应用场景:随着技术成熟,多模态AI将渗透到更多行业和场景,从内容创作到产品设计,从教育到医疗,改变人们的工作和生活方式。
结语
GLM-4.6V作为智谱AI推出的多模态大模型系列,不仅在技术上实现了多项突破,更在实际应用中展现了巨大价值。其创新性的视觉工具调用能力、超长上下文处理机制以及卓越的性能表现,使其成为多模态AI领域的重要里程碑。
随着GLM-4.6V的广泛应用,我们可以预见多模态AI将在内容创作、智能购物、前端开发、长文档理解等多个领域带来革命性变化。同时,其开源策略也将促进整个多模态AI生态的繁荣发展,推动人工智能技术的进步与创新。
在未来,GLM-4.6V及其后续产品将继续引领多模态AI的发展方向,为人类创造更智能、更便捷的数字体验。对于开发者和企业而言,把握这一技术趋势,积极探索GLM-4.6V的应用潜力,将在激烈的AI竞争中占据有利位置。