
近年来,人工智能领域最引人注目的进展莫过于大型语言模型(LLM)的崛起。这些模型在文本生成、语言翻译和问题解答等方面表现出色,但其内部运作机制却一直笼罩在神秘的面纱之下,被人们形象地称为“黑盒子”。不过,现在情况可能要发生改变了。AI研究公司Anthropic于5月29日开源了一款名为“电路追踪”(Circuit Tracing)的工具,旨在揭示大型语言模型内部决策过程的奥秘,为人工智能的透明化和可控性发展带来新的希望。
Anthropic的“电路追踪”工具的核心功能在于生成归因图(Attribution Graphs)。这种图能够清晰地展示大型语言模型在处理输入信息并生成输出结果的过程中,其内部的决策路径。换句话说,归因图就像一张地图,记录了模型在“思考”时所经过的每一个步骤。通过可视化模型内部的推理过程,研究人员可以更深入地了解AI是如何基于输入信息逐步形成最终输出的。
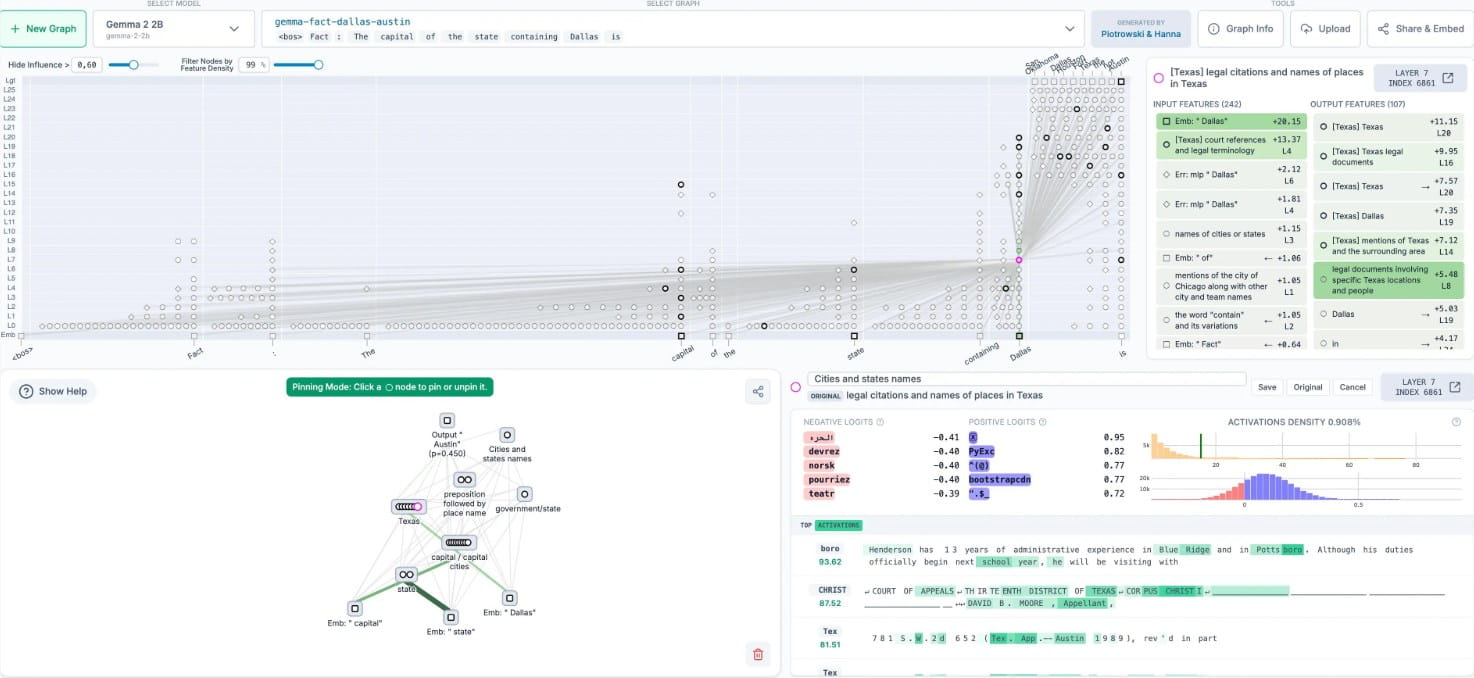
这种技术突破为研究人员提供了一个前所未有的“显微镜”,使他们能够观察模型内部的活动模式和信息流动,从而显著提升对AI决策机制的理解。Anthropic官方表示,研究人员可以利用该工具剖析大型语言模型的特定行为。例如,通过分析归因图,可以识别模型在执行任务时所依赖的关键特征或模式,从而更好地理解其能力与局限性。这不仅有助于优化模型性能,还能为确保AI系统在实际应用中的可靠性与安全性提供技术支持。
为了使研究人员能够更直观地分析归因图,Anthropic还结合了Neuronpedia交互式前端,为“电路追踪”工具提供强大的可视化支持。通过这个前端界面,用户可以轻松探索归因图的细节,观察模型内部的神经元活动,甚至可以通过修改特征值来测试不同的假设。例如,研究人员可以调整某些关键特征,并实时观察这些变化如何影响模型的输出,从而验证他们对模型行为的假设。
这种交互式设计极大地降低了研究门槛,即使是非专业人士也能通过直观的界面初步了解大型语言模型的复杂决策过程。Anthropic还提供了一份详细的操作指南,帮助用户快速上手,充分挖掘该工具的潜力。可以预见,随着越来越多的人开始使用“电路追踪”工具,我们将能够更全面、更深入地了解AI的“大脑”是如何运作的。
Anthropic的开源举措被认为是AI可解释性领域的重要里程碑。通过公开“电路追踪”工具的代码与方法,Anthropic不仅为学术界和开发者提供了研究大型语言模型的利器,还推动了AI技术的透明化发展。业内人士指出,理解大型语言模型的决策过程,不仅能帮助开发者设计更高效的AI系统,还能有效应对潜在的伦理与安全挑战,例如模型幻觉或偏见问题。例如,通过“电路追踪”工具,我们可以分析模型在生成文本时是否过度依赖某些关键词,或者是否存在对特定人群的歧视性偏见。
此外,该项目由Anthropic的研究团队与Decode Research合作完成,并在Anthropic Fellows计划的支持下推进,展现了开源社区与学术合作的巨大潜力。研究人员现在可以通过官方提供的资源,在开源权重模型上应用“电路追踪”工具,进一步拓展其应用场景。这意味着,任何对AI透明性感兴趣的研究者都可以利用这个工具来探索不同的模型,并为改进AI的可解释性做出贡献。
当然,我们也要清醒地认识到,“电路追踪”工具只是破解AI“黑盒子”难题的第一步。大型语言模型的内部结构极其复杂,即使有了“电路追踪”这样的工具,我们仍然面临着巨大的挑战。例如,如何从大量的归因图中提取有意义的信息?如何将这些信息转化为对模型行为的深刻理解?这些问题都需要研究人员付出大量的努力。
尽管如此,Anthropic的“电路追踪”工具仍然为我们打开了一扇通往AI内部世界的大门。正如业内专家所言,理解AI的内部机制是实现可信AI的关键一步。随着更多的研究人员和开发者加入到“电路追踪”工具的使用与优化中,AI的透明性与可控性有望进一步提升。这不仅将加速大型语言模型在各行业的落地应用,还可能为AI治理与伦理研究提供重要参考。
可以预见,在未来,随着AI技术的不断发展,我们将需要更加强大的工具来理解和控制AI的行为。Anthropic的“电路追踪”工具只是一个开始,我们期待未来能有更多类似的工具出现,共同推动AI技术向着更加透明、可信的方向发展。
更进一步:电路追踪的实际应用案例
为了更好地理解“电路追踪”工具的实际应用价值,我们可以设想以下几个案例:
- 优化模型性能:通过分析归因图,研究人员可以发现模型在处理特定任务时的瓶颈。例如,如果模型在进行情感分析时过度依赖某些词语,而忽略了上下文信息,那么研究人员就可以通过调整模型的训练数据或修改模型结构来解决这个问题,从而提高模型的情感分析准确率。
- 减少模型偏见:通过“电路追踪”工具,我们可以检测模型是否存在对特定人群的歧视性偏见。例如,如果模型在处理涉及不同种族或性别的问题时表现出明显的差异,那么研究人员就可以通过修改训练数据或引入新的算法来减少这种偏见,从而确保AI系统的公平性。
- 提高模型鲁棒性:通过分析归因图,我们可以了解模型在面对恶意攻击时的脆弱性。例如,如果模型容易受到对抗样本的攻击,那么研究人员就可以通过引入防御机制来提高模型的鲁棒性,从而确保AI系统在实际应用中的安全性。
- 解释模型行为:当模型做出令人困惑的决策时,“电路追踪”工具可以帮助我们理解其背后的原因。例如,如果一个自动驾驶系统突然做出异常的转向,那么我们可以通过分析归因图来了解系统在做出决策时所考虑的关键因素,从而找出潜在的问题并进行修复。
面临的挑战与未来展望
尽管“电路追踪”工具具有巨大的潜力,但我们也必须清醒地认识到,它仍然面临着许多挑战:
- 复杂性:大型语言模型的内部结构极其复杂,即使有了“电路追踪”这样的工具,我们仍然难以完全理解其运作机制。如何从大量的归因图中提取有意义的信息,并将其转化为对模型行为的深刻理解,仍然是一个巨大的挑战。
- 可扩展性:随着模型规模的不断扩大,“电路追踪”工具的计算成本也会越来越高。如何设计更高效的算法,以降低计算成本,使其能够应用于更大规模的模型,是一个亟待解决的问题。
- 通用性:目前的“电路追踪”工具主要针对特定类型的模型和任务。如何开发更通用的工具,使其能够应用于各种不同的模型和任务,仍然需要进一步的研究。
尽管面临着诸多挑战,但我们对AI的未来仍然充满信心。随着技术的不断进步,我们相信我们将能够克服这些挑战,并最终实现对AI的全面理解和控制。Anthropic的“电路追踪”工具只是一个开始,我们期待未来能有更多类似的工具出现,共同推动AI技术向着更加透明、可信的方向发展。这将为人工智能在各个领域的应用带来更广阔的前景,并为人类社会带来更大的福祉。
总结来说,Anthropic开源的“电路追踪”工具,无疑是向破解AI“黑盒子”迈出的重要一步。它为研究人员提供了一个强大的工具,可以深入探索大型语言模型的内部决策过程,从而更好地理解AI的能力与局限性。虽然这项技术仍处于发展初期,面临着诸多挑战,但它所蕴含的潜力是巨大的。我们有理由相信,随着“电路追踪”工具的不断完善和应用,AI的透明性与可控性将得到显著提升,从而为AI在各行各业的落地应用奠定坚实的基础。








