
AI技术革新浪潮:前沿动态深度解读
在科技日新月异的今天,人工智能(AI)正以惊人的速度渗透到我们生活的方方面面。从内容创作到音视频处理,再到数据分析和应用开发,AI技术正在以前所未有的方式重塑各行各业的格局。本文将深入探讨近期AI领域的几项重大进展,剖析其背后的技术原理、应用场景以及潜在影响。
阿里通义万相Wan2.1-VACE:视频编辑的未来
阿里巴巴推出的通义万相Wan2.1-VACE,是一款具有里程碑意义的开源视频编辑统一模型。它不仅支持多种分辨率和任务,还提供了一站式的视频创作体验。通过多模态输入机制,Wan2.1-VACE实现了高效灵活的视频编辑,极大地提高了创作效率。
技术解析:
- 多模态输入: 该模型能够理解和处理文本、图像等多种输入信息,从而实现更加智能化的视频编辑。
- 可控重绘: 基于人体姿态、运动光流等控制生成,支持主体和背景参考,使得视频编辑更加精准可控。
- 视频条件单元VCU: 通过统一多模态输入,实现多任务自由组合与灵活编辑,为视频创作带来了前所未有的自由度。
应用场景:
- 文生视频: 通过简单的文本描述,即可生成高质量的视频内容。
- 图像参考生成: 以图像为参考,生成风格相似或内容相关的视频。
- 局部编辑与视频扩展: 对视频的局部进行编辑,或者对视频进行扩展,满足不同的创作需求。
OpenAI GPT-4.1:代码能力的巅峰
OpenAI发布的GPT-4.1及其轻量级版本GPT-4.1mini,在编码能力和指令执行体验上实现了显著增强。GPT-4.1不仅能够更高效地处理复杂编程需求,还具备更快的运行速度,是开发者和指令处理场景的理想选择。GPT-4.1mini则在资源受限设备上也能流畅运行,为免费和付费用户提供了广泛的访问渠道。
技术解析:
- 强大的编码能力: GPT-4.1在处理复杂编程需求时表现出色,能够生成高质量的代码,并快速定位和修复错误。
- 高效的指令执行: 该模型能够准确理解用户的指令,并迅速执行,大大提高了工作效率。
- 多模态支持: GPT-4.1支持多种输入模态,包括文本、图像和音频,使得人机交互更加自然。
用户体验升级:
- 长按复制: 用户可以通过长按的方式复制文本,操作更加便捷。
- 表格复制: 支持复制表格数据,方便用户进行数据分析和处理。
- 流式传输: 采用流式传输技术,使得数据传输更加高效。
Stability AI:超轻量文字转语音模型
Stability AI发布的‘Adversarial Post-Training加速的快速文字转音频生成’模型,以其超轻量级的设计和卓越的性能引起了广泛关注。该模型仅有341M参数,却能在H100GPU上75毫秒生成12秒音频,在手机CPU上7秒完成同样任务,性能十分出色。
技术解析:
- ARC后训练方法: 该方法不基于蒸馏,能够有效提升模型生成速度与质量。
- 轻量化设计: 模型采用轻量化设计,支持手机本地运行,大幅提升了移动端创意应用体验。
- 音频转音频功能: 实现风格迁移,激发更多创作灵感。
应用前景:
- 移动应用: 该模型可以在手机等移动设备上运行,为移动应用提供高质量的语音合成服务。
- 内容创作: 创作者可以利用该模型快速生成各种风格的音频内容。
- 语音助手: 该模型可以用于开发智能语音助手,提供更加自然流畅的语音交互体验。

可灵大模型:视频生成领域的领跑者
Poe发布的2025年春季AI模型使用趋势报告显示,中国快手的可灵多款视频生成模型在文生视频领域表现突出,市场份额高达30%,领先于Runway等竞争者。其中,可灵2.0模型仅三周就占据了21%的使用比例。
市场表现:
- 市场份额领先: 可灵大模型在文生视频领域市场份额达30%,领先Runway等竞争者。
- 增长迅速: 可灵2.0模型自4月发布后三周内即占据21%视频生成市场。
- 用户规模庞大: 可灵AI全球用户超过2200万,月活跃用户增长25倍,生成视频与图片数量显著增加。
技术优势:
- 高质量的视频生成: 可灵大模型能够生成高质量、高清晰度的视频内容。
- 丰富的创作功能: 该模型提供了丰富的创作功能,满足用户不同的创作需求。
- 易于使用: 用户可以通过简单的操作,快速生成所需的视频内容。
微软 WizardLM 团队加入腾讯:混元大模型的强大助力
微软的人工智能研究团队WizardLM整体加入腾讯AI实验室的“混元”团队,标志着腾讯在大模型领域进一步发力。WizardLM团队不仅带来了多项技术突破,还通过开源模型展示了其研发实力。此次合作无疑将为腾讯混元大模型注入新的活力,提升其在AI领域的竞争力。
合作意义:
- 技术实力增强: WizardLM团队的加入,将显著增强腾讯混元团队的技术实力。
- 研发能力提升: 双方的合作将加速腾讯在大模型领域的研发进程。
- 市场竞争力增强: 此次合作将提升腾讯在AI市场的竞争力,使其在全球AI竞争中占据更为主导的地位。
腾讯混元图像2.0:AI视觉的新突破
腾讯混元大模型团队宣布,混元图像2.0将在5月16日发布,这是腾讯在AI视觉领域的重要突破,以‘更智能、更开放、更中国’为核心理念。混元图像2.0的发布,标志着腾讯在AI视觉领域取得了新的进展,将为创作者和企业带来更强大的AI驱动的视觉生产工具。
核心理念:
- 更智能: 混元图像2.0将具备更强大的智能能力,能够更好地理解和处理图像。
- 更开放: 该工具将更加开放,方便用户进行二次开发和定制。
- 更中国: 混元图像2.0将更加注重中国文化特色,为中国用户提供更加符合其需求的AI视觉服务。
上海人工智能标识生态联盟:构建可信AI环境
上海市成立的人工智能标识生态联盟,旨在推动人工智能领域的标识技术发展,提高生成内容的透明度和安全性。该联盟通过政策解读和企业合作,为构建可信的人工智能环境奠定基础。小红书、MiniMax等企业参与标识工作实践,探索多种内容的标识方案并积累治理经验,为人工智能的健康发展保驾护航。
联盟目标:
- 提升透明度: 提高AI生成内容的透明度,让用户清楚地了解内容的来源和生成方式。
- 增强安全性: 增强AI生成内容的安全性,防止被用于非法用途。
- 构建可信环境: 为构建可信的人工智能环境奠定基础,促进人工智能的健康发展。
Lightricks LTX-Video-13B:高清AI视频的飞跃
以色列科技公司Lightricks发布的开源AI视频生成模型LTX-Video-13B精炼模型,以130亿参数为基础,结合多尺度渲染技术和高效量化优化,将视频生成速度提升至10秒以内,同时保持高质量输出。LTX-Video-13B的发布,为AI视频生成领域带来了新的突破,使得高质量AI视频的生成更加快速和便捷。
技术特点:
- 多尺度渲染技术: 采用多尺度渲染技术,能够在短时间内生成高清视频。
- 高效量化优化: 通过高效量化优化,降低了模型对硬件资源的需求。
- 开源模型: 作为开源模型,LTX-Video-13B降低了AI视频制作的门槛,使得更多人能够参与到AI视频创作中来。
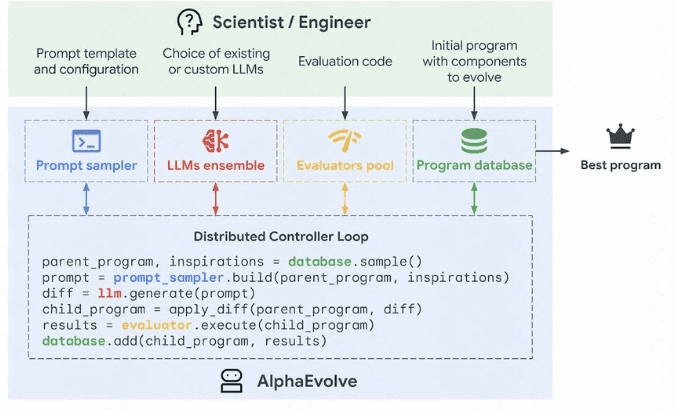
谷歌AlphaEvolve:AI自进化的突破
谷歌DeepMind发布的AlphaEvolve是一款结合Gemini大语言模型与进化算法的AI编码代理,它在多个领域展现了强大的自优化能力,包括数据中心调度、芯片设计、AI训练以及数学研究。AlphaEvolve的发布,标志着AI在自进化方面取得了重要进展,为解决复杂问题提供了新的思路。
应用领域:
- 数据中心调度: AlphaEvolve优化数据中心调度,回收0.7%全球算力,节省运营成本。
- 芯片设计: 该模型可以用于优化芯片设计,提高芯片的性能和效率。
- AI训练: 提升AI训练效率,Gemini模型训练速度提升32.5%,展现强大自我优化能力。
- 数学研究: AlphaEvolve可以用于解决复杂的数学难题,为数学研究提供新的工具。
腾讯元宝浏览器插件:高效浏览体验
腾讯元宝浏览器插件尝鲜版上线Chrome平台,提供悬浮球、常驻侧边栏和划词工具栏等功能,提升网页浏览与信息处理效率。元宝浏览器插件的发布,旨在为用户提供更加高效便捷的网页浏览体验。
核心功能:
- 悬浮球: 支持一键翻译和总结网页内容,轻松跨越语言障碍并节省阅读时间。
- 常驻侧边栏: 可高效答疑,支持截图提问,大幅提升信息获取效率。
- 划词工具栏: 实现选中文本后的即时搜索或翻译,让信息处理更流畅。
结论
人工智能正在以前所未有的速度发展,并在各个领域展现出强大的应用潜力。从视频编辑、语音合成到AI自进化和高效浏览,AI技术的每一次突破都为我们带来了新的惊喜和可能性。随着技术的不断进步,我们有理由相信,AI将在未来发挥更加重要的作用,为人类创造更加美好的生活。








