
在人工智能领域,大型语言模型(LLM)的快速发展无疑是一场革命。然而,这些模型的内部运作机制长期以来如同一个“黑盒子”,隐藏着决策过程的奥秘。近日,AI研究公司Anthropic发布了一项开源工具——“电路追踪”(Circuit Tracing),旨在揭示LLM内部的决策过程,为AI的透明化和可控性发展迈出了重要一步。
“电路追踪”工具通过生成归因图(Attribution Graphs),可视化地展示了LLM在处理输入到生成输出过程中的内部决策路径。这种归因图能够清晰地呈现模型的推理步骤,揭示AI如何基于输入信息逐步形成最终输出。研究人员可以利用这一工具深入观察模型的内部活动模式和信息流动,从而更全面地理解AI的决策机制。
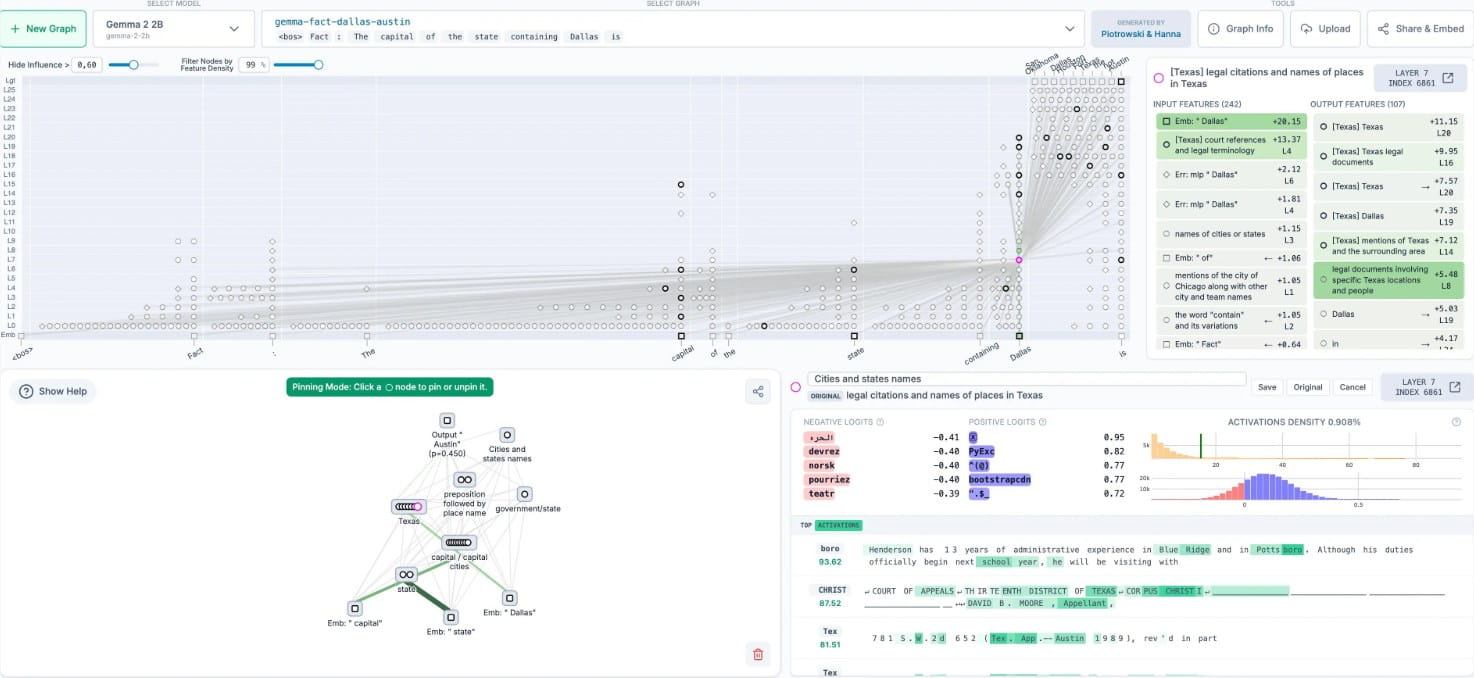
Anthropic官方介绍称,研究人员可以利用“电路追踪”工具剖析LLM的特定行为。通过分析归因图,可以识别模型在执行任务时所依赖的关键特征或模式,从而更好地理解其能力与局限性。这不仅有助于优化模型性能,还能为确保AI系统在实际应用中的可靠性和安全性提供技术支持。
为了更直观地分析归因图,Anthropic还结合了Neuronpedia交互式前端,为“电路追踪”工具提供强大的可视化支持。用户可以通过这一前端界面轻松探索归因图的细节,观察模型内部的神经元活动,甚至通过修改特征值来测试不同的假设。例如,研究人员可以调整某些关键特征,实时观察这些变化如何影响模型的输出,从而验证对模型行为的假设。
这种交互式设计大大降低了研究门槛,使得非专业人士也能通过直观的界面初步了解LLM的复杂决策过程。Anthropic还提供了一份详细的操作指南,帮助用户快速上手,充分挖掘工具的潜力。
Anthropic的开源举措被认为是AI可解释性领域的重要里程碑。通过公开“电路追踪”工具的代码与方法,Anthropic为学术界和开发者提供了研究LLM的利器,并推动了AI技术的透明化发展。业内人士指出,理解LLM的决策过程不仅能帮助开发者设计更高效的AI系统,还能有效应对潜在的伦理与安全挑战,例如模型幻觉或偏见问题。
“电路追踪”工具的发布,无疑为AI研究人员提供了一把开启LLM“黑盒子”的钥匙。长期以来,人们对于AI的决策过程知之甚少,这不仅限制了AI技术的进一步发展,也带来了一系列伦理和安全问题。通过“电路追踪”工具,研究人员可以更深入地了解模型的内部运作机制,从而更好地优化模型性能,并及时发现和解决潜在的问题。
此外,“电路追踪”工具的开源也为AI领域的合作与创新提供了新的平台。通过共享代码和方法,Anthropic鼓励更多的研究人员和开发者参与到LLM的研究中来,共同推动AI技术的进步。这种开源模式有望加速AI技术的发展,并为解决AI领域面临的挑战提供新的思路。
“电路追踪”工具的应用前景十分广阔。除了用于优化模型性能和解决伦理安全问题外,该工具还可以用于教育和培训领域。通过可视化地展示LLM的决策过程,可以帮助学生和从业者更好地理解AI技术,并为他们提供实践操作的机会。
当然,“电路追踪”工具也面临着一些挑战。首先,该工具的复杂性较高,需要一定的专业知识才能使用。其次,由于LLM的规模庞大,归因图的生成和分析可能需要大量的计算资源。此外,如何有效地利用归因图来改进模型性能和解决伦理安全问题,还需要进一步的研究。
尽管存在挑战,“电路追踪”工具的发布仍然是AI领域的一项重大突破。它为我们打开了LLM“黑盒子”的一角,让我们得以窥见AI决策过程的内部运作机制。随着技术的不断发展和完善,“电路追踪”工具将在AI领域发挥越来越重要的作用,为AI的透明化、可控性和安全性发展做出更大的贡献。
Anthropic的这一项目由研究团队与Decode Research合作完成,并在Anthropic Fellows计划的支持下推进,展现了开源社区与学术合作的巨大潜力。研究人员可以通过官方提供的资源,在开源权重模型上应用“电路追踪”工具,进一步拓展其应用场景。
Anthropic发布的“电路追踪”工具,为破解AI“黑盒子”难题提供了新的可能性。理解AI的内部机制是实现可信AI的关键一步。随着更多研究人员和开发者加入到这一工具的使用与优化中,AI的透明性与可控性有望进一步提升。这不仅将加速LLM在各行业的落地应用,还可能为AI治理与伦理研究提供重要参考。
可以预见,随着“电路追踪”等工具的不断涌现,AI技术将变得越来越透明和可控。这将有助于我们更好地利用AI技术,为人类社会创造更大的价值。
更深入地探索AI决策过程
“电路追踪”工具的核心在于其能够生成归因图,这种图能够清晰地展示LLM在处理输入信息并最终生成输出的过程中所采取的内部决策路径。通过这些归因图,研究人员能够像使用显微镜一样,深入观察模型的内部活动模式和信息流动,从而显著提升对AI决策机制的理解。这种能力对于优化模型、确保AI系统的可靠性和安全性至关重要。
交互式分析与假设验证
为了便于研究人员更直观地分析归因图,Anthropic将“电路追踪”工具与Neuronpedia交互式前端相结合,提供了强大的可视化支持。用户可以通过这个前端界面轻松地探索归因图的细节,观察模型内部的神经元活动,甚至可以通过修改特征值来测试不同的假设。例如,研究人员可以调整某些关键特征,实时观察这些变化如何影响模型的输出,从而验证他们对模型行为的假设。这种交互式设计极大地降低了研究门槛,使得非专业人士也能通过直观的界面初步了解LLM的复杂决策过程。
开源的意义与影响
Anthropic的开源举措在AI可解释性领域具有里程碑意义。通过公开“电路追踪”工具的代码与方法,Anthropic不仅为学术界和开发者提供了研究LLM的利器,也推动了AI技术的透明化发展。业内人士普遍认为,理解LLM的决策过程对于设计更高效的AI系统至关重要,同时也有助于应对潜在的伦理与安全挑战,如模型幻觉或偏见问题。开源还有助于促进社区合作,让更多的人参与到AI安全和可解释性的研究中来。
面临的挑战与未来的发展方向
尽管“电路追踪”工具具有很大的潜力,但它也面临着一些挑战。其中之一是计算复杂性。由于LLM通常包含数十亿甚至数千亿的参数,生成和分析归因图需要大量的计算资源。此外,如何有效地利用归因图来改进模型性能和解决伦理安全问题仍然是一个开放的研究问题。
展望未来,我们可以期待“电路追踪”工具在以下几个方面取得进展:
- 更高效的算法:开发更高效的算法,以降低生成和分析归因图所需的计算资源。
- 更智能的可视化:改进可视化技术,使用户能够更轻松地理解和解释归因图。
- 自动化分析:开发自动化工具,以帮助研究人员识别模型中的关键电路和模式。
- 集成到开发流程中:将“电路追踪”工具集成到AI模型的开发流程中,以便开发者能够在早期发现和修复潜在的问题。
结论
Anthropic的“电路追踪”工具是AI可解释性领域的一项重要进展。它为研究人员提供了一个强大的工具,可以深入了解LLM的内部运作机制。通过开源这一工具,Anthropic正在推动AI技术的透明化和可控性发展,并鼓励社区合作解决AI安全和伦理问题。虽然“电路追踪”工具仍然面临一些挑战,但它为我们提供了一个窥探AI“黑盒子”的窗口,并有望在未来几年内取得更大的进展。随着AI技术的不断发展,我们有理由相信,通过不懈的努力,我们最终将能够理解和控制AI,从而更好地利用它来造福人类社会。








