
在人工智能领域,模型推理速度一直是制约其广泛应用的关键因素。近日,科技巨头英伟达与麻省理工学院(MIT)及香港大学携手推出了名为 Fast-dLLM 的创新框架,该框架旨在显著提升扩散模型(Diffusion-based LLMs)的推理速度,最高可达 27.6 倍,为人工智能的应用提供了更为强大的技术支持。这一突破性的进展无疑为 AI 技术的未来发展注入了新的活力。
扩散模型的挑战与机遇
扩散模型作为一种新兴的生成模型,被视为传统自回归模型的有力竞争者。与自回归模型不同,扩散模型采用双向注意力机制(Bidirectional Attention Mechanisms),理论上能够通过同步生成多个词元(Multi-token Generation)来加速解码过程。这种并行处理能力使得扩散模型在处理长文本和复杂序列时具有潜在的优势。然而,在实际应用中,扩散模型的推理速度常常不及自回归模型,这主要是由于每次生成步骤都需要重新计算全部注意力状态,导致计算成本过高。此外,多词元同步解码时,词元间的依赖关系容易被破坏,从而影响生成质量。这些问题严重制约了扩散模型在实际应用中的表现。
为了克服这些挑战,研究人员一直在积极探索各种优化策略,力求充分发挥扩散模型的潜力。Fast-dLLM 框架的出现,正是这一探索过程中的一项重要成果。它通过引入一系列创新技术,有效地解决了扩散模型在推理速度和生成质量方面存在的瓶颈问题,为扩散模型在实际应用中与自回归模型竞争提供了有力的支持。
Fast-dLLM 框架的创新
Fast-dLLM 框架的核心在于其引入的两项重要创新:块状近似 KV 缓存机制和置信度感知并行解码策略。这两项技术的结合,使得 Fast-dLLM 能够在显著提升推理速度的同时,保证生成质量。
1. 块状近似 KV 缓存机制
块状近似 KV 缓存机制是 Fast-dLLM 框架的关键组成部分。该机制通过将序列划分为多个块(Blocks),预先计算并存储各块的激活值(KV Activations),并在后续解码中重复利用。这种方式显著减少了计算冗余,提升了效率。传统的注意力机制需要在每一步解码时都重新计算所有词元的注意力权重,这导致了大量的重复计算。而块状近似 KV 缓存机制通过将序列分成小块,并预先计算这些块的 KV 值,从而避免了重复计算,大大提高了计算效率。
为了进一步提升性能,Fast-dLLM 还引入了 DualCache 版本。DualCache 版本进一步缓存前后缀词元(Prefix and Suffix Tokens),利用相邻推理步骤的高度相似性来提升处理速度。在实际应用中,相邻的推理步骤往往具有很高的相似性,这意味着它们之间存在大量的重复计算。DualCache 版本通过缓存前后缀词元,可以有效地利用这些相似性,从而进一步减少计算量,提高推理速度。
2. 置信度感知并行解码策略
置信度感知并行解码策略是 Fast-dLLM 框架的另一项重要创新。该策略根据设定的阈值(Confidence Threshold),选择性地解码高置信度的词元,避免同步采样带来的依赖冲突,从而确保生成质量。在传统的并行解码策略中,所有的词元都是同时生成的,这可能会导致词元之间的依赖关系被破坏,从而影响生成质量。而置信度感知并行解码策略通过只解码高置信度的词元,可以有效地避免这种依赖冲突,从而保证生成质量。
置信度感知并行解码策略的核心在于如何准确地评估词元的置信度。Fast-dLLM 框架采用了一种基于模型输出概率的置信度评估方法。具体来说,它将模型输出的概率值作为词元的置信度,只有当概率值高于设定的阈值时,该词元才会被解码。这种方法简单有效,能够很好地反映词元的生成质量。
卓越的性能表现
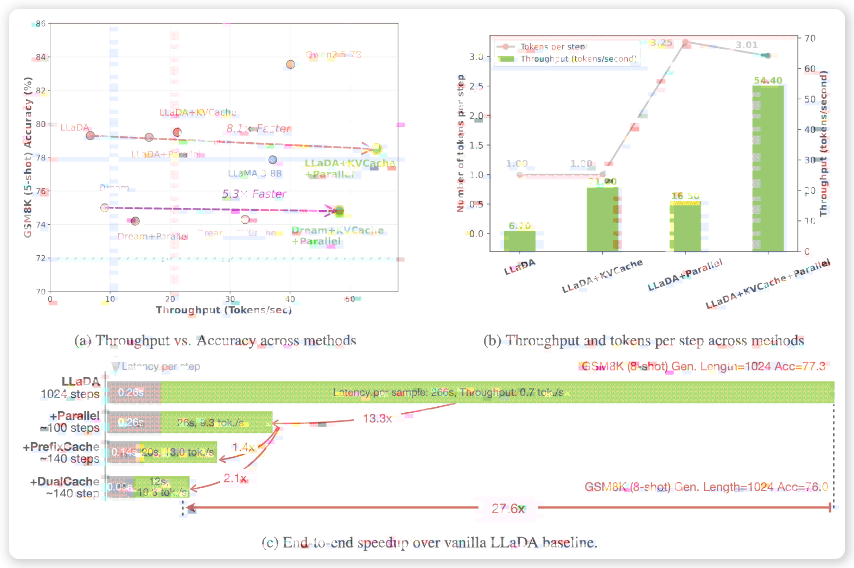
为了验证 Fast-dLLM 框架的有效性,英伟达团队在多项基准测试中对其进行了评估。结果表明,Fast-dLLM 在多项基准测试中表现出色,充分证明了其在提升推理速度和保证生成质量方面的优势。
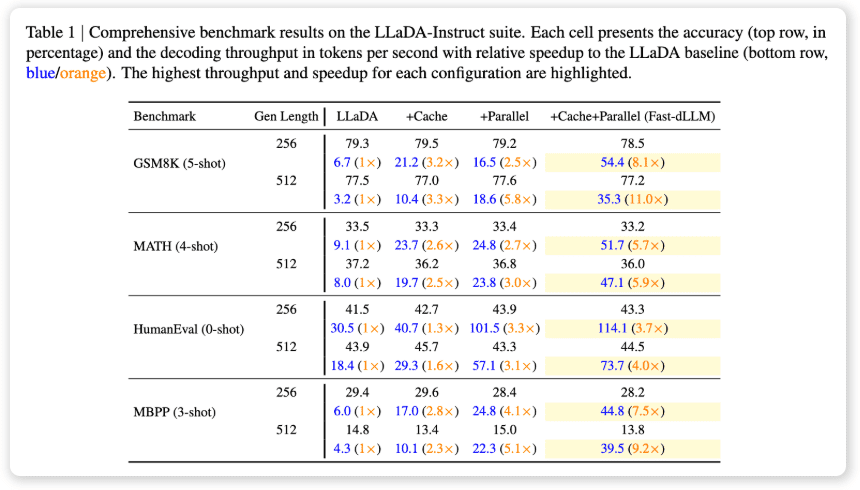
在 GSM8K 数据集上,生成长度为 1024 词元时,其 8-shot 配置实现了 27.6 倍的速度提升,准确率达 76.0%。GSM8K 数据集是一个常用的数学推理数据集,它包含了大量的数学问题和相应的解答。Fast-dLLM 在 GSM8K 数据集上的出色表现,表明其在处理复杂的推理任务时具有很强的能力。
在 MATH 基准测试中,加速倍数为 6.5 倍,准确率约为 39.3%。MATH 基准测试是另一个常用的数学推理数据集,它包含了更复杂的数学问题。Fast-dLLM 在 MATH 基准测试中的表现虽然不如在 GSM8K 数据集上那么出色,但仍然取得了显著的加速效果,同时保持了较高的准确率。
在 HumanEval 和 MBPP 测试中,分别实现了 3.2 倍和 7.8 倍的加速,准确率维持在 54.3% 和基线水平附近。HumanEval 和 MBPP 测试是常用的代码生成数据集,它们包含了大量的代码片段和相应的描述。Fast-dLLM 在 HumanEval 和 MBPP 测试中的表现表明,其在代码生成任务中也具有一定的潜力。
总体来看,Fast-dLLM 在提升速度的同时,准确率仅下降 1-2 个百分点,有效平衡了速度与质量。这意味着 Fast-dLLM 不仅能够显著提升推理速度,而且能够保证生成质量,使其在实际应用中具有很高的价值。
结论与展望
Fast-dLLM 框架的推出,是人工智能领域的一项重要进展。它通过解决推理效率和解码质量的问题,使扩散模型在实际语言生成任务中具备了与自回归模型竞争的实力,为未来更广泛的应用奠定了基础。随着这一技术的推广,我们有望看到人工智能在更多领域的实际应用,例如:
- 自然语言处理:Fast-dLLM 可以用于提升机器翻译、文本摘要、对话生成等自然语言处理任务的效率和质量。
- 代码生成:Fast-dLLM 可以用于加速代码生成过程,提高代码生成的准确率和效率。
- 图像生成:Fast-dLLM 可以扩展到图像生成领域,用于生成高质量的图像。
- 药物发现:Fast-dLLM 可以用于加速药物发现过程,预测药物的性质和活性。
总之,Fast-dLLM 框架的出现,为人工智能的未来发展开辟了新的道路。我们期待着 Fast-dLLM 在未来的应用中能够取得更大的成功,为人类带来更多的福祉。








