
在人工智能领域,NVIDIA 近期发布了 Canary-Qwen-2.5B 模型,这款集成了自动语音识别(ASR)和大语言模型(LLM)的混合模型,在语音识别准确率上取得了显著突破,其词错误率(WER)达到了 5.63%,登顶 Hugging Face OpenASR 排行榜。该模型采用 CC-BY 许可,兼具商业授权和开源特性,为企业级语音 AI 应用的开发降低了门槛。
技术突破:统一语音理解和语言处理
Canary-Qwen-2.5B 的发布标志着语音识别技术的一个重要进展。它将语音转录和语言理解集成到一个统一的模型架构中,使得直接从音频进行摘要和问答等下游任务成为可能。这种创新架构将传统的 ASR 流程转变为一个统一的工作流程,无需将转录和后处理分开进行。
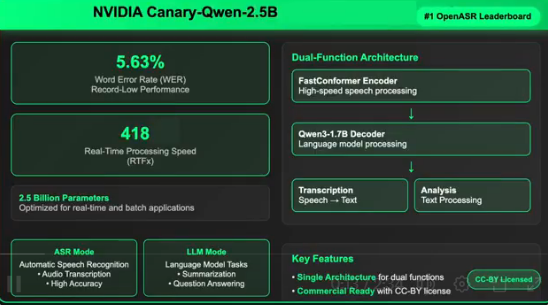
关键性能指标
Canary-Qwen-2.5B 模型在多个维度上都刷新了纪录:
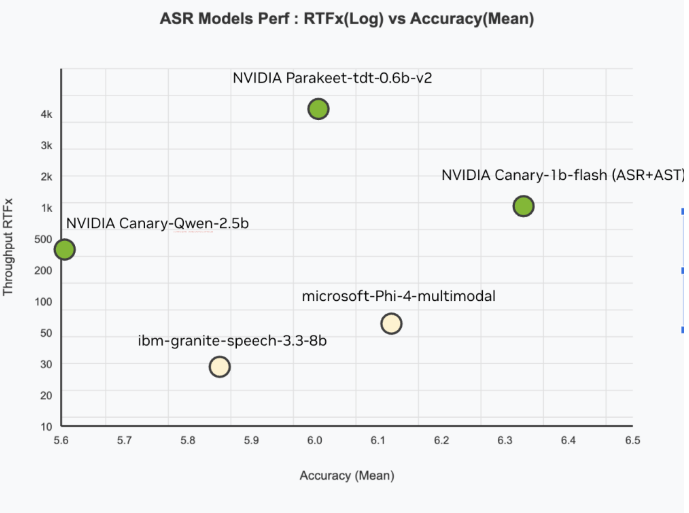
- 准确率:在 Hugging Face OpenASR 排行榜上实现了 5.63% 的 WER,是目前最低的。
- 速度:实现了 418 倍的实时处理速度(RTFx),这意味着它可以比实际时间快 418 倍的速度处理音频。
- 效率:模型仅包含 25 亿个参数,与其他性能较差的大型模型相比,更加紧凑。
- 训练规模:该模型基于一个包含 23.4 万小时的英语语音数据集进行训练。
创新的混合架构设计
Canary-Qwen-2.5B 的核心创新在于其混合架构,该架构由两个关键组件构成:
- FastConformer 编码器:专为低延迟和高精度转录而设计。
- Qwen3-1.7B LLM 解码器:这是一个未经修改的预训练大语言模型,通过一个适配器接收音频转录的 tokens。
这种适配器设计确保了模块化,允许 Canary 编码器分离,并使 Qwen3-1.7B 能够作为独立的 LLM 运行,以执行基于文本的任务。通过单一的部署,该模型可以处理口语和书面输入的下游语言任务,从而增强了多模态的灵活性。
企业级应用价值
Canary-Qwen-2.5B 采用 CC-BY 许可,这为它打开了广阔的商业应用场景,使其有别于许多受非商业许可限制的研究模型:
- 企业转录服务:提供快速、准确的语音转录,满足企业日常运营需求。
- 音频知识提取:从语音数据中提取关键信息,为企业决策提供支持。
- 实时会议纪要:自动生成会议纪要,提高会议效率。
- 语音控制 AI 代理:开发可以通过语音控制的 AI 代理,提升用户体验。
- 合规文档处理:在医疗、法律和金融等领域,处理符合法规要求的文档。
该模型的 LLM 感知解码能力还增强了标点、大小写和上下文准确性,这些通常是传统 ASR 输出的弱点。Canary-Qwen-2.5B 可以更准确地理解语音内容,从而生成更清晰、更易于理解的文本。
硬件兼容性和部署灵活性
Canary-Qwen-2.5B 针对各种 NVIDIA GPU 进行了优化,支持从数据中心 A100 和 H100 到工作站 RTX PRO6000,甚至消费级 GeForce RTX 5090 的硬件。这种跨硬件的可扩展性使其适用于云推理和内部边缘工作负载。
开源驱动行业发展
通过开源模型及其训练程序,NVIDIA 研究团队旨在促进社区驱动的语音 AI 发展。开发人员可以混合搭配其他 NeMo 兼容的编码器和 LLM,为新的领域或语言创建自定义混合模型。这种开放性将加速语音 AI 技术的创新和应用。
Canary-Qwen-2.5B 标志着以 LLM 为中心的 ASR 新时代的开始,其中 LLM 不再是后处理器,而是集成到语音转文本过程中的核心代理。这种方法反映了更广泛的代理模型趋势——这些系统能够基于真实世界的多模态输入进行全面的理解和决策。
NVIDIA 的 Canary-Qwen-2.5B 不仅仅是一个 ASR 模型,而是一个将语音理解与通用语言模型集成的蓝图。凭借 SoTA 性能、商业可用性和开放创新途径,该版本有望成为企业、开发人员和研究人员解锁下一代语音优先 AI 应用的基础工具。
应用场景深度分析
为了更全面地理解 Canary-Qwen-2.5B 的实际应用价值,以下将从几个关键行业入手,探讨其潜在的应用场景。
金融服务
- 合规性与风险管理:在金融领域,合规性至关重要。Canary-Qwen-2.5B 能够高效地转录和分析电话录音、会议记录以及其他语音数据,帮助金融机构识别潜在的违规行为和风险因素。通过提取关键信息,如交易指令、客户投诉和内部沟通,该模型可以协助进行欺诈检测、洗钱预防以及其他合规性检查。此外,其 LLM 感知解码能力能够确保转录文本的准确性和完整性,从而减少因误解或遗漏信息而导致的合规风险。
- 客户服务优化:Canary-Qwen-2.5B 可以应用于客户服务中心,自动转录客户与客服代表之间的对话。这不仅可以帮助企业更好地了解客户需求和痛点,还可以通过分析对话内容来评估客服代表的表现,从而有针对性地进行培训和改进。此外,该模型还可以用于自动生成客户服务报告,为管理层提供决策支持。
医疗保健
- 电子病历管理:在医疗领域,医生需要花费大量时间记录患者的病历信息。Canary-Qwen-2.5B 可以通过语音转录技术,将医生的口述记录快速、准确地转换为电子病历。这不仅可以节省医生宝贵的时间,还可以减少手动输入错误,提高病历信息的质量。此外,该模型还可以用于分析病历数据,帮助医生更好地了解患者的病情,从而制定更有效的治疗方案。
- 远程医疗支持:随着远程医疗的兴起,Canary-Qwen-2.5B 可以为远程医疗提供强大的技术支持。通过转录医生与患者之间的语音交流,该模型可以帮助医生更好地了解患者的病情,并为患者提供个性化的医疗建议。此外,该模型还可以用于自动生成远程医疗报告,为医生和患者提供参考。
法律服务
- 法律文件处理:法律行业涉及大量的文件处理工作,包括合同、判决书、庭审记录等。Canary-Qwen-2.5B 可以通过语音转录技术,将庭审录音、律师口述等语音信息转换为文本,从而提高法律文件处理的效率。此外,该模型还可以用于分析法律文件,帮助律师更好地了解案情,从而制定更有效的辩护策略。
- 法律咨询服务:Canary-Qwen-2.5B 可以应用于在线法律咨询平台,自动转录用户与律师之间的语音交流。这不仅可以帮助律师更好地了解用户的问题,还可以通过分析对话内容来评估用户的法律需求,从而提供更专业的法律建议。此外,该模型还可以用于自动生成法律咨询报告,为用户提供参考。
技术细节深入剖析
Canary-Qwen-2.5B 的技术创新不仅体现在其混合架构上,还体现在其训练方法和优化策略上。以下将深入剖析该模型的技术细节,以便更好地理解其性能优势。
FastConformer 编码器
- 低延迟设计:FastConformer 编码器采用了特殊的低延迟设计,使其能够快速处理语音输入,从而实现实时转录。这种低延迟设计对于需要实时反馈的应用场景非常重要,如在线会议、实时翻译等。
- 高精度转录:FastConformer 编码器采用了先进的声学建模技术,能够准确地将语音信号转换为文本。通过优化模型结构和训练方法,该编码器可以有效地降低词错误率,提高转录精度。
Qwen3-1.7B LLM 解码器
- 上下文理解:Qwen3-1.7B LLM 解码器是一个预训练的大语言模型,具有强大的上下文理解能力。它可以根据上下文信息来纠正语音转录中的错误,从而提高转录的准确性和流畅性。
- 语言生成:Qwen3-1.7B LLM 解码器还可以生成自然、流畅的文本。通过学习大量的文本数据,该解码器可以模仿人类的语言风格,从而生成更易于理解的文本。
混合架构的优势
- 模块化设计:Canary-Qwen-2.5B 的混合架构采用了模块化设计,使得编码器和解码器可以独立进行优化和升级。这种模块化设计不仅可以提高模型的灵活性,还可以降低模型的维护成本。
- 端到端优化:Canary-Qwen-2.5B 采用了端到端优化策略,使得编码器和解码器可以协同工作,从而实现最佳的转录效果。通过联合训练编码器和解码器,该模型可以有效地提高转录精度和流畅性。
未来展望
Canary-Qwen-2.5B 的发布是语音 AI 领域的一个重要里程碑。它不仅在性能上取得了显著突破,还在商业应用和开源方面做出了重要贡献。随着语音 AI 技术的不断发展,我们可以期待 Canary-Qwen-2.5B 在未来发挥更大的作用。
- 更多语言支持:未来,Canary-Qwen-2.5B 可以扩展到支持更多的语言,从而满足全球用户的需求。
- 更多应用场景:未来,Canary-Qwen-2.5B 可以应用于更多的场景,如智能家居、智能交通等,从而为人们的生活带来更多便利。
- 更强大的性能:未来,Canary-Qwen-2.5B 可以通过优化模型结构和训练方法,进一步提高性能,从而实现更准确、更流畅的语音转录。








