
在人工智能领域,NVIDIA 推出的 Canary-Qwen-2.5B 模型无疑是一颗耀眼的新星。这款自动语音识别(ASR)和语言模型(LLM)的混合模型,以其卓越的性能和创新的架构,刷新了行业标准,为企业级语音 AI 的发展开辟了新的道路。Canary-Qwen-2.5B 不仅在 Hugging Face OpenASR 排行榜上名列前茅,更以其商业许可和开源特性,吸引了业界的广泛关注。
技术融合:语音理解与语言处理的统一
Canary-Qwen-2.5B 的发布,是技术发展的一个重要里程碑。它将语音转录和语言理解整合到一个统一的模型架构中,使得从音频直接执行摘要和问答等下游任务成为可能。这种创新架构打破了传统 ASR 流程的局限,将原本独立的转录和后处理阶段融合为一个整体的工作流程,极大地提高了效率和准确性。
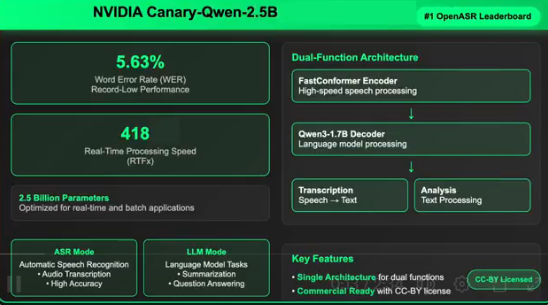
关键性能指标:多项纪录的刷新
Canary-Qwen-2.5B 在多个关键性能指标上都创下了新的纪录:
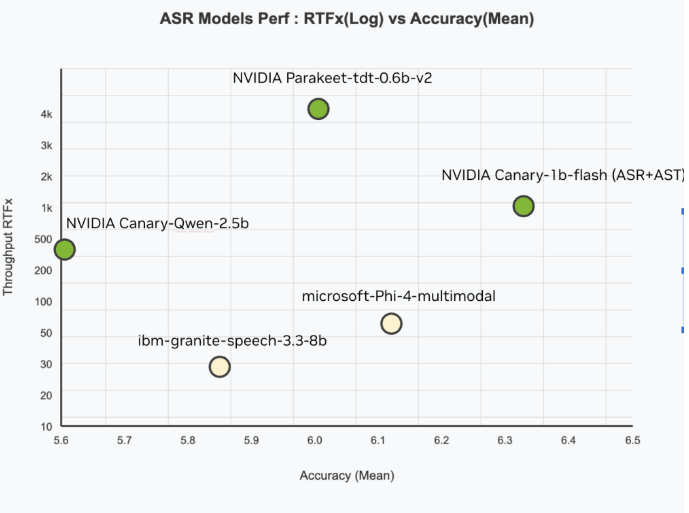
- 准确性:在 Hugging Face OpenASR 排行榜上,实现了 5.63% 的词错率(WER),为历史最低。
- 速度:RTFx 达到 418,意味着处理音频的速度比实时速度快 418 倍。
- 效率:模型仅包含 25 亿参数,相比于性能较差的大型模型,更加紧凑高效。
- 训练规模:模型基于 234,000 小时的多样化英语语音数据集进行训练,保证了其广泛的适用性和强大的泛化能力。
创新混合架构设计:FastConformer 编码器与 Qwen3-1.7B LLM 解码器
Canary-Qwen-2.5B 的核心创新在于其混合架构,它由两个关键组件构成:
- FastConformer 编码器:专门用于低延迟和高精度转录,能够快速准确地将语音转换为文本。
- Qwen3-1.7B LLM 解码器:这是一个未经修改的预训练大型语言模型,通过适配器接收音频转录标记。这种设计保证了解码器能够充分利用预训练的语言知识,提高转录的质量和准确性。
这种适配器设计确保了模块化,允许 Canary 编码器分离,并将 Qwen3-1.7B 作为独立 LLM 运行用于基于文本的任务。这意味着单一部署即可处理口语和书面输入的下游语言任务,极大地提升了多模态灵活性。例如,在智能客服场景中,该模型既可以处理用户的语音咨询,也可以处理用户的文本输入,实现全方位的服务。
企业级应用价值:开启商业应用新篇章
与许多受非商业许可约束的研究模型不同,Canary-Qwen-2.5B 采用 CC-BY 许可发布,为广泛的商业应用开启了大门。这意味着企业可以自由地使用、修改和分发该模型,而无需担心版权问题。这无疑将极大地促进语音 AI 技术在各行各业的应用。
Canary-Qwen-2.5B 的企业级应用场景包括:
- 企业转录服务:为企业提供高质量的语音转录服务,例如会议记录、访谈记录等。
- 基于音频的知识提取:从音频数据中提取关键信息,例如市场调研、客户反馈等。
- 实时会议总结:在会议进行过程中,实时生成会议摘要,提高会议效率。
- 语音控制的 AI 代理:开发语音控制的 AI 代理,例如智能助手、智能家居等。
- 符合法规要求的文档处理:在医疗保健、法律、金融等领域,对语音数据进行处理,确保符合相关法规要求。
该模型的 LLM 感知解码功能还提升了标点符号、大写字母和上下文准确度,这些往往是传统 ASR 输出的薄弱环节。这意味着 Canary-Qwen-2.5B 不仅能够准确地转录语音,还能够理解语音的含义,从而生成更加自然流畅的文本。
硬件兼容性与部署灵活性:云端与边缘的完美结合
Canary-Qwen-2.5B 针对多种 NVIDIA GPU 进行了优化,支持从数据中心的 A100、H100 到工作站 RTX PRO6000,再到消费级 GeForce RTX5090 等硬件。这种跨硬件类别的扩展性使其适用于云推理和内部边缘工作负载。这意味着企业可以根据自身的需求,选择合适的硬件平台来部署该模型,从而实现最佳的性能和成本效益。
开源推动行业发展:社区驱动的语音 AI 进步
通过开源该模型及其训练方案,NVIDIA 研究团队旨在促进社区驱动的语音 AI 进步。开发者可以混合搭配其他兼容 NeMo 的编码器和 LLM,为新领域或语言创建特定任务的混合模型。这意味着开发者可以基于 Canary-Qwen-2.5B,开发出各种各样的语音 AI 应用,从而推动整个行业的发展。
Canary-Qwen-2.5B 的发布,也为以 LLM 为中心的 ASR 开创了先河。在这种模式下,LLM 不再是后处理器,而是集成在语音转文本流程中的核心代理。这种方法反映了向代理模型迈进的更广阔趋势——能够基于现实世界多模态输入进行全面理解和决策的系统。这意味着未来的语音 AI 系统将更加智能、更加灵活,能够更好地满足用户的需求。
NVIDIA 的 Canary-Qwen-2.5B 不仅仅是一个 ASR 模型,更是将语音理解与通用语言模型相集成的蓝图。凭借 SoTA 性能、商业可用性以及开放的创新途径,该版本有望成为企业、开发者和研究人员解锁下一代语音优先 AI 应用的基础工具。
案例分析:Canary-Qwen-2.5B 在金融领域的应用
在金融领域,Canary-Qwen-2.5B 可以应用于客户服务、风险管理和合规性等多个方面。
- 智能客服:Canary-Qwen-2.5B 可以用于构建智能客服系统,自动处理客户的语音咨询。该系统可以准确地识别客户的问题,并提供相应的解决方案,从而提高客户满意度和降低客服成本。
- 风险管理:Canary-Qwen-2.5B 可以用于分析电话录音,识别潜在的欺诈行为。该模型可以识别语音中的关键词和语调变化,从而发现可疑的交易和行为。
- 合规性:Canary-Qwen-2.5B 可以用于记录和分析交易员的语音交流,确保其符合相关法规要求。该模型可以自动转录语音,并提取关键信息,例如交易指令和风险披露。
Canary-Qwen-2.5B 的未来展望
Canary-Qwen-2.5B 的发布,标志着语音 AI 技术进入了一个新的发展阶段。随着技术的不断进步,Canary-Qwen-2.5B 将在更多的领域得到应用,为人们的生活和工作带来更多的便利。未来,我们可以期待 Canary-Qwen-2.5B 在以下几个方面取得更大的突破:
- 多语言支持:目前,Canary-Qwen-2.5B 主要支持英语。未来,我们可以期待该模型能够支持更多的语言,从而满足全球用户的需求。
- 更强的鲁棒性:在嘈杂的环境中,语音识别的准确率会受到影响。未来,我们可以期待 Canary-Qwen-2.5B 能够具有更强的鲁棒性,从而在各种环境下都能实现高精度的语音识别。
- 更低的延迟:在实时语音交互场景中,延迟是一个重要的指标。未来,我们可以期待 Canary-Qwen-2.5B 能够实现更低的延迟,从而提供更加流畅的语音交互体验。
总之,NVIDIA 的 Canary-Qwen-2.5B 模型以其卓越的性能、创新的架构和广泛的应用前景,成为了语音 AI 领域的一颗耀眼的新星。我们有理由相信,在 Canary-Qwen-2.5B 的推动下,语音 AI 技术将迎来更加美好的未来。
技术细节深入:Canary-Qwen-2.5B 的内部机制
为了更深入地了解 Canary-Qwen-2.5B 的强大之处,我们不妨深入探讨其内部机制。该模型的核心在于其混合架构,它巧妙地结合了 FastConformer 编码器和 Qwen3-1.7B LLM 解码器的优势。
FastConformer 编码器是一种专门为语音识别设计的神经网络结构。它采用了 Conformer 模块,能够有效地捕捉语音信号中的局部和全局特征。同时,FastConformer 编码器还采用了 FastEmit 技术,能够以低延迟的方式输出语音转录结果。
Qwen3-1.7B LLM 解码器是一个预训练的大型语言模型。它在大量的文本数据上进行了训练,掌握了丰富的语言知识。通过适配器,Qwen3-1.7B LLM 解码器可以接收 FastConformer 编码器输出的语音转录标记,并将其转化为自然流畅的文本。
这种混合架构的设计,使得 Canary-Qwen-2.5B 既能够实现高精度的语音识别,又能够生成高质量的文本。同时,由于 Qwen3-1.7B LLM 解码器是一个预训练的模型,因此 Canary-Qwen-2.5B 具有很强的泛化能力,能够适应不同的语音和文本风格。
总结:Canary-Qwen-2.5B 的重要意义
Canary-Qwen-2.5B 的发布,不仅仅是一个技术上的突破,更具有重要的行业意义。
- 推动语音 AI 技术的发展:Canary-Qwen-2.5B 的卓越性能,将激励更多的研究人员和开发者投入到语音 AI 领域的研究中,从而推动整个行业的发展。
- 降低语音 AI 应用的门槛:Canary-Qwen-2.5B 的商业许可和开源特性,使得企业可以更加方便地使用和部署该模型,从而降低了语音 AI 应用的门槛。
- 促进语音 AI 在各行各业的应用:Canary-Qwen-2.5B 的广泛适用性和强大的泛化能力,使得其可以在各行各业得到应用,从而为人们的生活和工作带来更多的便利。
总而言之,NVIDIA 的 Canary-Qwen-2.5B 模型是语音 AI 领域的一个里程碑式的成果。它以其卓越的性能、创新的架构和广泛的应用前景,成为了语音 AI 领域的一颗耀眼的新星。我们有理由相信,在 Canary-Qwen-2.5B 的推动下,语音 AI 技术将迎来更加美好的未来。








